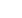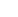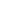随着人工智能技术的不断发展,语音识别作为其中一个重要的研究领域,得到了广泛的关注和应用。特别是在语音信号分类和模式识别中,神经网络的应用表现出了巨大的潜力。本文将介绍一种基于反向传播(BP)神经网络的语音识别系统。通过训练神经网络,利用语音信号的特征进行分类,完成不同语音类别的识别任务。本文详细介绍了该系统的设计过程,包括数据预处理、BP神经网络模型的构建、训练过程、分类结果分析等。最终,通过实验结果对该系统的表现进行了总结与思考。
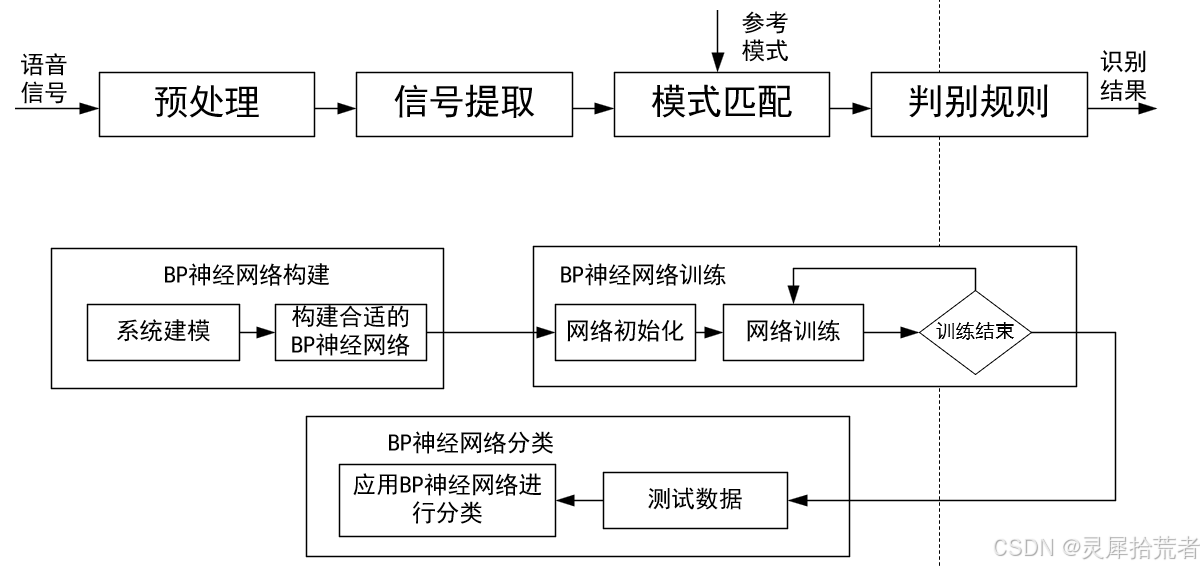
BP神经网络由输入层、隐含层和输出层构成,其核心计算流程如下:
(1)神经元激活函数
采用Sigmoid函数实现非线性映射:
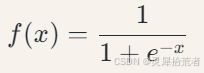
其导数特性便于反向传播计算:
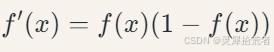
(2)隐含层输出计算
对于第𝑗个隐含层神经元:
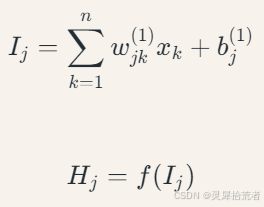
其中𝑤𝑗𝑘(1) 为输入层到隐含层的权重,𝑏𝑗(1) 为偏置项。
(3)输出层计算
输出层采用线性激活:
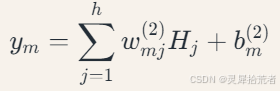
其中ℎ 为隐含层神经元数量,𝑚 为输出类别数。
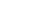
(1)损失函数定义
采用均方误差(MSE)衡量预测偏差:
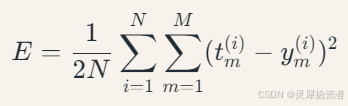
其中𝑡𝑚 为真实标签的one-hot编码。
(2)权重更新规则
通过梯度下降法逐层反向修正参数:
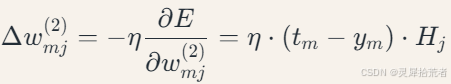
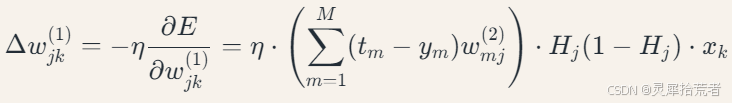
其中𝜂 为学习率。
本文的 MATLAB 代码主要分为以下几个部分:
%% 该代码为基于BP网络的语言识别%% 清空环境变量clcclear%% 训练数据预测数据提取及归一化%下载四类语音信号load data1 c1load data2 c2load data3 c3load data4 c4%四个特征信号矩阵合成一个矩阵data(1:500,:)=c1(1:500,:);data(501:1000,:)=c2(1:500,:);data(1001:1500,:)=c3(1:500,:);data(1501:2000,:)=c4(1:500,:);%从1到2000间随机排序k=rand(1,2000);[m,n]=sort(k);%输入输出数据input=data(:,2:25);output1 =data(:,1);%把输出从1维变成4维output=zeros(2000,4);for i=1:2000 switch output1(i) case 1 output(i,:)=[1 0 0 0]; case 2 output(i,:)=[0 1 0 0]; case 3 output(i,:)=[0 0 1 0]; case 4 output(i,:)=[0 0 0 1]; endend%随机提取1500个样本为训练样本,500个样本为预测样本input_train=input(n(1:1500),:)';output_train=output(n(1:1500),:)';input_test=input(n(1501:2000),:)';output_test=output(n(1501:2000),:)';%输入数据归一化[inputn,inputps]=mapminmax(input_train);说明:
clc: 清空命令窗口。clear: 清空工作区变量。load data1 c1: 加载语音数据,c1 存储第一类语音信号的特征。data(1:500,:)=c1(1:500,:): 将四类语音信号的特征合并到一个矩阵 data 中。k=rand(1,2000): 生成一个 1x2000 的随机数向量。[m,n]=sort(k): 对随机数向量进行排序,n 存储排序后的索引。input=data(:,2:25): 提取输入特征,这里假设每条语音数据有 25 个特征,第一个特征是类别标签。output1 =data(:,1): 提取类别标签。output=zeros(2000,4): 将类别标签转换为 one-hot 编码。input_train=input(n(1:1500),:): 随机提取 1500 个样本作为训练样本。input_test=input(n(1501:2000),:): 随机提取 500 个样本作为测试样本。[inputn,inputps]=mapminmax(input_train): 对输入数据进行归一化,将数据缩放到 [-1, 1] 区间。%% 网络结构初始化innum=24;midnum=25;outnum=4; %权值初始化w1=rands(midnum,innum);b1=rands(midnum,1);w2=rands(midnum,outnum);b2=rands(outnum,1);w2_1=w2;w2_2=w2_1;w1_1=w1;w1_2=w1_1;b1_1=b1;b1_2=b1_1;b2_1=b2;b2_2=b2_1;%学习率xite=0.1;alfa=0.01;loopNumber=10;I=zeros(1,midnum);Iout=zeros(1,midnum);FI=zeros(1,midnum);dw1=zeros(innum,midnum);db1=zeros(1,midnum);说明:
innum=24: 输入层神经元数量,对应输入特征的数量。midnum=25: 隐藏层神经元数量。outnum=4: 输出层神经元数量,对应语音类别的数量。w1=rands(midnum,innum): 初始化输入层到隐藏层的权值矩阵。b1=rands(midnum,1): 初始化隐藏层神经元的偏置。w2=rands(midnum,outnum): 初始化隐藏层到输出层的权值矩阵。b2=rands(outnum,1): 初始化输出层神经元的偏置。xite=0.1: 学习率。loopNumber=10: 迭代次数。%% 网络训练E=zeros(1,loopNumber);for ii=1:loopNumber E(ii)=0; for i=1:1:1500 %% 网络预测输出 x=inputn(:,i); % 隐含层输出 for j=1:1:midnum I(j)=inputn(:,i)'*w1(j,:)'+b1(j); Iout(j)=1/(1+exp(-I(j))); end % 输出层输出 yn=w2'*Iout'+b2; %% 权值阀值修正 %计算误差 e=output_train(:,i)-yn; E(ii)=E(ii)+sum(abs(e)); %计算权值变化率 dw2=e*Iout; db2=e'; for j=1:1:midnum S=1/(1+exp(-I(j))); FI(j)=S*(1-S); end for k=1:1:innum for j=1:1:midnum dw1(k,j)=FI(j)*x(k)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4)); db1(j)=FI(j)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4)); end end w1=w1_1+xite*dw1'; b1=b1_1+xite*db1'; w2=w2_1+xite*dw2'; b2=b2_1+xite*db2'; w1_2=w1_1;w1_1=w1; w2_2=w2_1;w2_1=w2; b1_2=b1_1;b1_1=b1; b2_2=b2_1;b2_1=b2; endend说明:
E=zeros(1,loopNumber): 初始化误差向量。for ii=1:loopNumber: 迭代训练 loopNumber 次。x=inputn(:,i): 提取第 i 个训练样本的输入特征。I(j)=inputn(:,i)'*w1(j,:)'+b1(j): 计算隐藏层神经元的输入。Iout(j)=1/(1+exp(-I(j))): 计算隐藏层神经元的输出,使用 Sigmoid 函数作为激活函数。yn=w2'*Iout'+b2: 计算输出层神经元的输出。e=output_train(:,i)-yn: 计算输出层神经元的误差。dw2=e*Iout: 计算隐藏层到输出层的权值变化率。db2=e': 计算输出层神经元的偏置变化率。FI(j)=S*(1-S): 计算 Sigmoid 函数的导数。dw1(k,j)=FI(j)*x(k)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4)): 计算输入层到隐藏层的权值变化率。db1(j)=FI(j)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4)): 计算隐藏层神经元的偏置变化率。w1=w1_1+xite*dw1': 更新输入层到隐藏层的权值。b1=b1_1+xite*db1': 更新隐藏层神经元的偏置。w2=w2_1+xite*dw2': 更新隐藏层到输出层的权值。b2=b2_1+xite*db2': 更新输出层神经元的偏置。%% 语音特征信号分类inputn_test=mapminmax('apply',input_test,inputps);fore=zeros(4,500);for ii=1:1 for i=1:500%1500 %隐含层输出 for j=1:1:midnum I(j)=inputn_test(:,i)'*w1(j,:)'+b1(j); Iout(j)=1/(1+exp(-I(j))); end fore(:,i)=w2'*Iout'+b2; endend%% 结果分析%根据网络输出找出数据属于哪类output_fore=zeros(1,500);for i=1:500 output_fore(i)=find(fore(:,i)==max(fore(:,i)));end%BP网络预测误差error=output_fore-output1(n(1501:2000))';%画出预测语音种类和实际语音种类的分类图figure(1)plot(output_fore,'r')hold onplot(output1(n(1501:2000))','b')legend('预测语音类别','实际语音类别')%画出误差图figure(2)plot(error)title('BP网络分类误差','fontsize',12)xlabel('语音信号','fontsize',12)ylabel('分类误差','fontsize',12)%print -dtiff -r600 1-4k=zeros(1,4); %找出判断错误的分类属于哪一类for i=1:500 if error(i)~=0 [b,c]=max(output_test(:,i)); switch c case 1 k(1)=k(1)+1; case 2 k(2)=k(2)+1; case 3 k(3)=k(3)+1; case 4 k(4)=k(4)+1; end endend%找出每类的个体和kk=zeros(1,4);for i=1:500 [b,c]=max(output_test(:,i)); switch c case 1 kk(1)=kk(1)+1; case 2 kk(2)=kk(2)+1; case 3 kk(3)=kk(3)+1; case 4 kk(4)=kk(4)+1; endend%正确率rightridio=(kk-k)./kk;disp('正确率')disp(rightridio);说明:
inputn_test=mapminmax('apply',input_test,inputps): 对测试数据进行归一化,使用训练数据的归一化参数。fore=zeros(4,500): 初始化预测结果矩阵。output_fore=zeros(1,500): 根据网络输出找出数据属于哪类。error=output_fore-output1(n(1501:2000))': 计算预测误差。plot(output_fore,'r'): 画出预测语音类别和实际语音类别的分类图。plot(error): 画出误差图。k=zeros(1,4): 找出判断错误的分类属于哪一类。kk=zeros(1,4): 找出每类的个体和。rightridio=(kk-k)./kk: 计算正确率。%% 该代码为基于BP网络的语言识别%% 清空环境变量clcclear%% 训练数据预测数据提取及归一化%下载四类语音信号load data1 c1load data2 c2load data3 c3load data4 c4%四个特征信号矩阵合成一个矩阵data(1:500,:)=c1(1:500,:);data(501:1000,:)=c2(1:500,:);data(1001:1500,:)=c3(1:500,:);data(1501:2000,:)=c4(1:500,:);%从1到2000间随机排序k=rand(1,2000);[m,n]=sort(k);%输入输出数据input=data(:,2:25);output1 =data(:,1);%把输出从1维变成4维output=zeros(2000,4);for i=1:2000 switch output1(i) case 1 output(i,:)=[1 0 0 0]; case 2 output(i,:)=[0 1 0 0]; case 3 output(i,:)=[0 0 1 0]; case 4 output(i,:)=[0 0 0 1]; endend%随机提取1500个样本为训练样本,500个样本为预测样本input_train=input(n(1:1500),:)';output_train=output(n(1:1500),:)';input_test=input(n(1501:2000),:)';output_test=output(n(1501:2000),:)';%输入数据归一化[inputn,inputps]=mapminmax(input_train);%% 网络结构初始化innum=24;midnum=25;outnum=4; %权值初始化w1=rands(midnum,innum);b1=rands(midnum,1);w2=rands(midnum,outnum);b2=rands(outnum,1);w2_1=w2;w2_2=w2_1;w1_1=w1;w1_2=w1_1;b1_1=b1;b1_2=b1_1;b2_1=b2;b2_2=b2_1;%学习率xite=0.1;alfa=0.01;loopNumber=10;I=zeros(1,midnum);Iout=zeros(1,midnum);FI=zeros(1,midnum);dw1=zeros(innum,midnum);db1=zeros(1,midnum);%% 网络训练E=zeros(1,loopNumber);for ii=1:loopNumber E(ii)=0; for i=1:1:1500 %% 网络预测输出 x=inputn(:,i); % 隐含层输出 for j=1:1:midnum I(j)=inputn(:,i)'*w1(j,:)'+b1(j); Iout(j)=1/(1+exp(-I(j))); end % 输出层输出 yn=w2'*Iout'+b2; %% 权值阀值修正 %计算误差 e=output_train(:,i)-yn; E(ii)=E(ii)+sum(abs(e)); %计算权值变化率 dw2=e*Iout; db2=e'; for j=1:1:midnum S=1/(1+exp(-I(j))); FI(j)=S*(1-S); end for k=1:1:innum for j=1:1:midnum dw1(k,j)=FI(j)*x(k)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4)); db1(j)=FI(j)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4)); end end w1=w1_1+xite*dw1'; b1=b1_1+xite*db1'; w2=w2_1+xite*dw2'; b2=b2_1+xite*db2'; w1_2=w1_1;w1_1=w1; w2_2=w2_1;w2_1=w2; b1_2=b1_1;b1_1=b1; b2_2=b2_1;b2_1=b2; endend %% 语音特征信号分类inputn_test=mapminmax('apply',input_test,inputps);fore=zeros(4,500);for ii=1:1 for i=1:500%1500 %隐含层输出 for j=1:1:midnum I(j)=inputn_test(:,i)'*w1(j,:)'+b1(j); Iout(j)=1/(1+exp(-I(j))); end fore(:,i)=w2'*Iout'+b2; endend%% 结果分析%根据网络输出找出数据属于哪类output_fore=zeros(1,500);for i=1:500 output_fore(i)=find(fore(:,i)==max(fore(:,i)));end%BP网络预测误差error=output_fore-output1(n(1501:2000))';%画出预测语音种类和实际语音种类的分类图figure(1)plot(output_fore,'r')hold onplot(output1(n(1501:2000))','b')legend('预测语音类别','实际语音类别')%画出误差图figure(2)plot(error)title('BP网络分类误差','fontsize',12)xlabel('语音信号','fontsize',12)ylabel('分类误差','fontsize',12)%print -dtiff -r600 1-4k=zeros(1,4); %找出判断错误的分类属于哪一类for i=1:500 if error(i)~=0 [b,c]=max(output_test(:,i)); switch c case 1 k(1)=k(1)+1; case 2 k(2)=k(2)+1; case 3 k(3)=k(3)+1; case 4 k(4)=k(4)+1; end endend%找出每类的个体和kk=zeros(1,4);for i=1:500 [b,c]=max(output_test(:,i)); switch c case 1 kk(1)=kk(1)+1; case 2 kk(2)=kk(2)+1; case 3 kk(3)=kk(3)+1; case 4 kk(4)=kk(4)+1; endend%正确率rightridio=(kk-k)./kk;disp('正确率')disp(rightridio);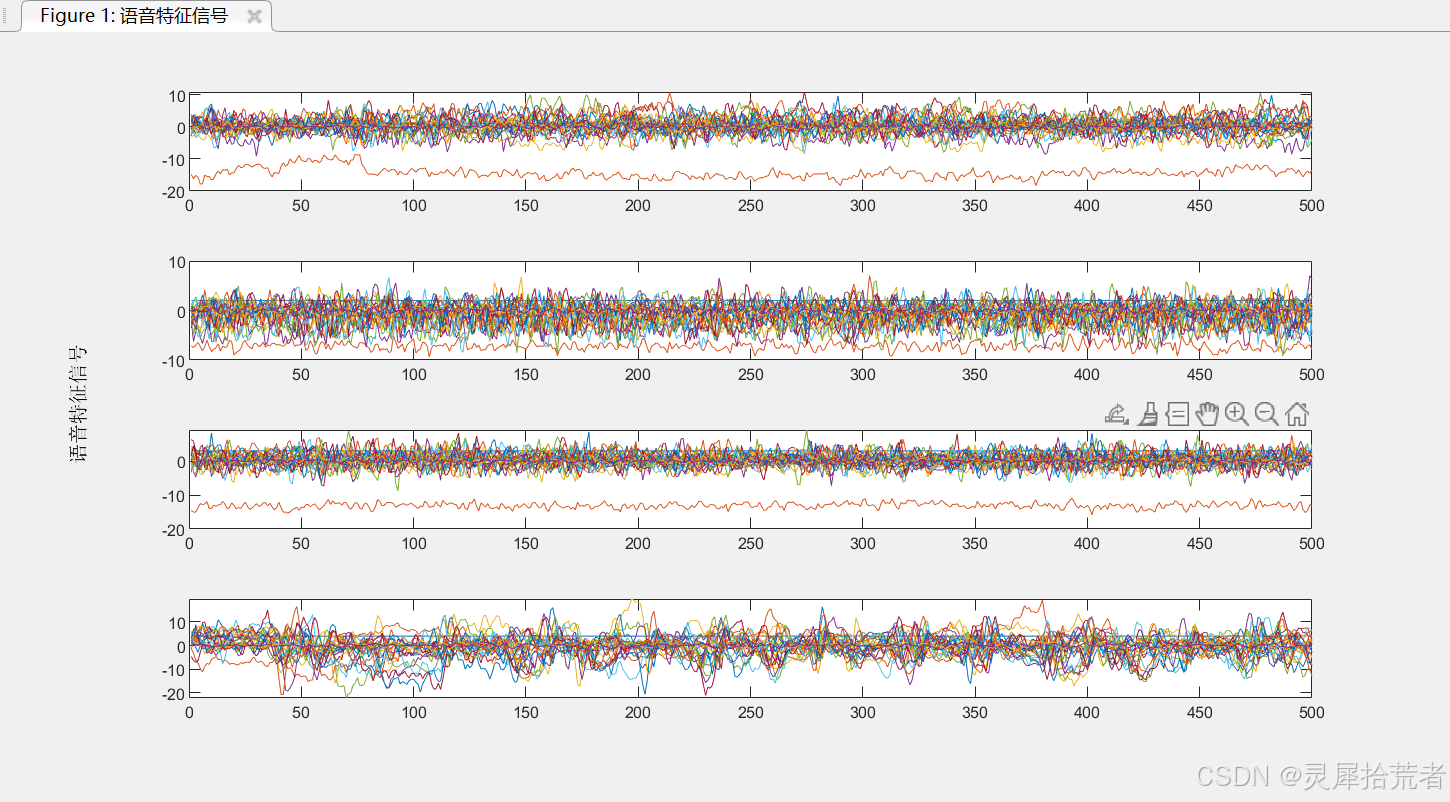
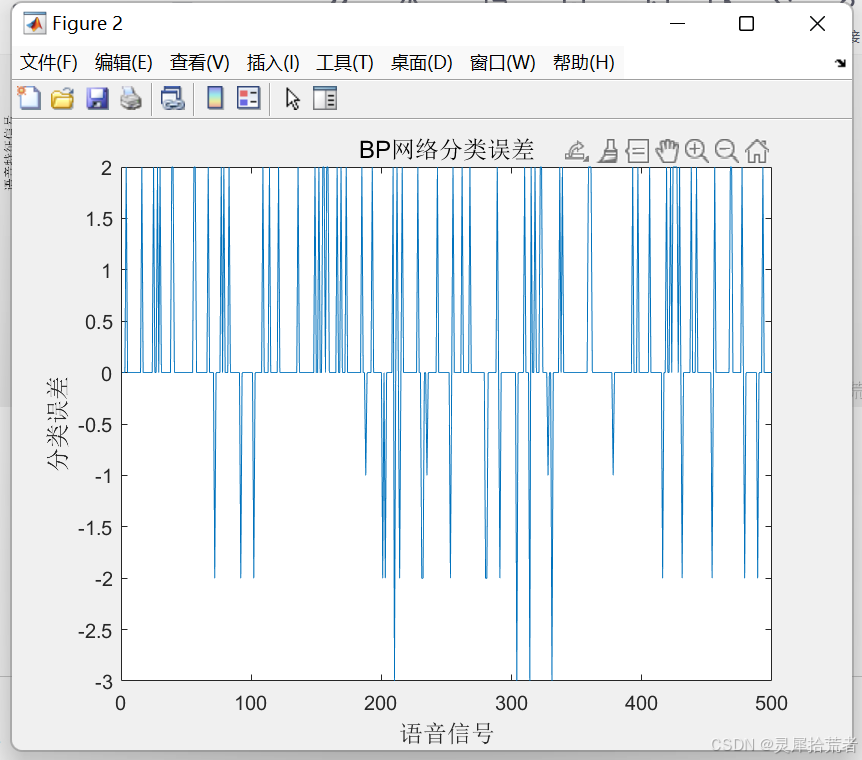
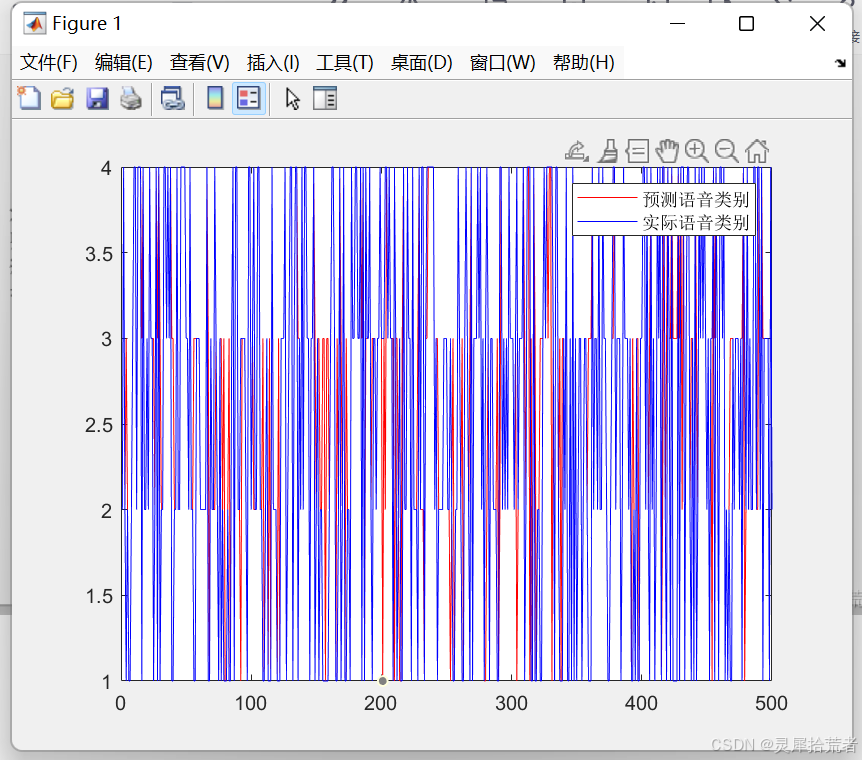
从实验结果可以看出,基于BP神经网络的语音识别系统能够较好地识别四类语音信号。然而,该系统也存在一些不足之处,如:
本文以一段基于BP神经网络的语言识别MATLAB代码为例,深入剖析BP神经网络在语音识别中的应用,包括其原理、实现过程和性能分析.文章中的观点仅代表个人见解,供读者参考交流。若有任何问题或建议,欢迎在评论区留言讨论,共同促进技术进步。
如果您对神经网络、群智能算法及人工智能技术感兴趣,请关注我们的公众号【灵犀拾荒者】,获取更多前沿技术文章、实战案例及技术分享!欢迎点赞、收藏并转发,与更多朋友一起探讨与交流!点赞+收藏+关注,公众号后台留言【免费资料】关键词可获免费资源。